
Category Archives: Uncategorized
Finally get my Hackintosh (High Sierra) working!!!!!!
After serveral years of studies and trial, I finally get a Hackintosh working with spared parts. I know the cost for a proper Mac Book Pro is far below my time cost, but it is really a great learning experience for me.
Before I start, here is my hardware list, I just purchase 2nd parts, with my old parts and my brother-in-law decomissioned parts.
Intel E3-1275 (Sandy Bridge)
Biostar B75S3E (B75 mATX board)
Asus GT1030 2GB
Crucial BX500 240G SSD
Basically it covers the following major steps. I use Hackintosh Zone High Sierra for installation.
https://www.hackintoshzone.com/files/file/1044-niresh-high-sierra/
1. Setup the BIOS according to the Hackintosh guide
2. Setup the Hackintosh with relevant settings
3. Upgarde to 10.13.6 (3 Updates)
4. Use Clover Configurator to setup the SMIBIOS, prepare for Web Drivers and enable SSDT flags for power management
5. Use Multibeast to install a bunch of Drivers
6. Install Nvidia Web Driver to enable the graphics acceleration of GT1030
7. Convert APFS and configure mount point noatime to preserve SSD wearing
8. Homebrew
9. Enjoy!!
The detail procedure is as followed
2. Setup the Hackintosh with relevant settings
I have done the following settings in the configuration for Installing the base MacOS
a. Enable Network
b. Enable USB Support for Intel 7/8/9 family USB
c. Disable NullCPUPowerManagement (enable by Default)
4. Use Clover Configurator to setup the SMIBIOS, prepare for Web Drivers and enable SSDT flags for power management
Primarily, this settings is for SSDT to enable power management in Clover Configurator. My Settings are as followed.
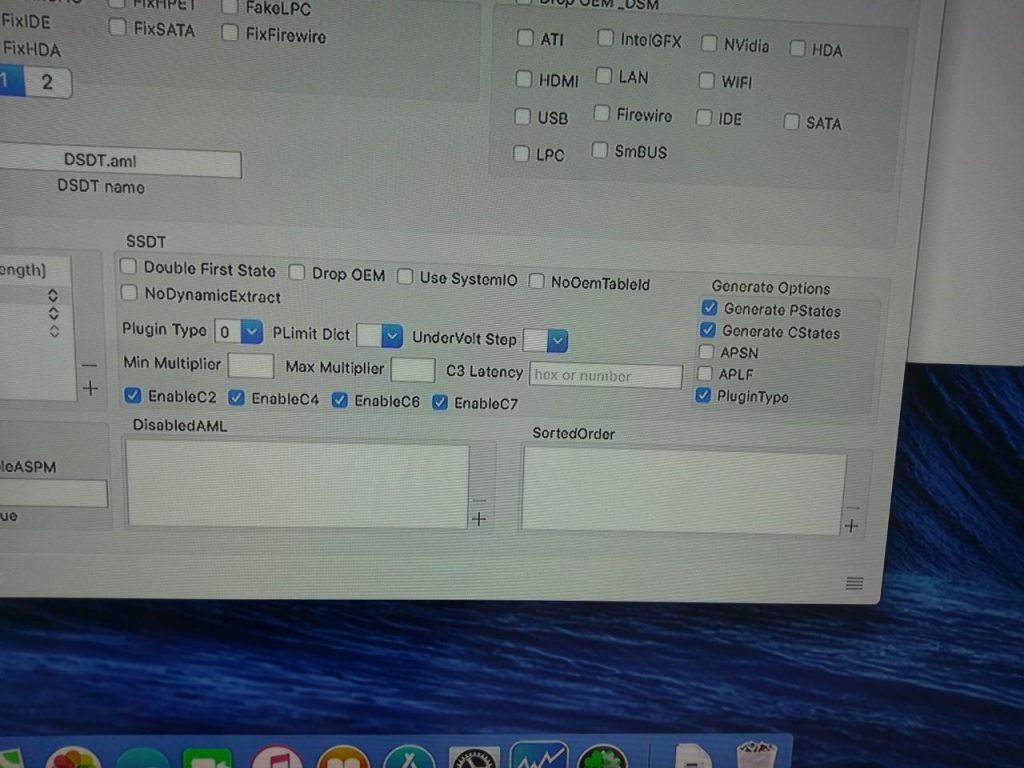
5. Use Multibeast to install a bunch of Drivers.
Multibeast is used to install a bunch of drivers to fit my hardware. The list is as followed.
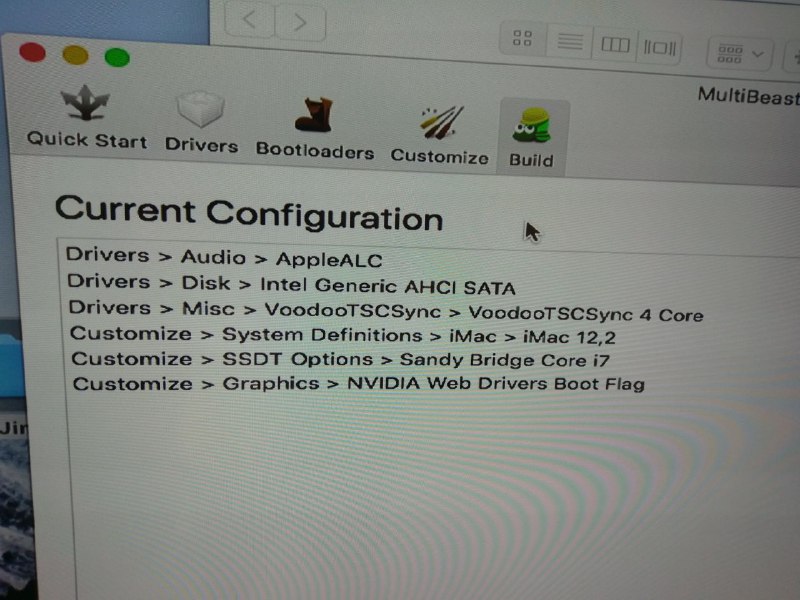
6. Nvidia Web Drivers
Nvidia Web Driver is provided by nVidia (not Apple) to drive the latest GeForce series graphics card. Unfortunate, it supports only up to High Sierra, no Majove or Catalina. We could download here. It has to match with your MacOS version, including sub-version and patch level
https://www.tonymacx86.com/nvidia-drivers/
7. APFS and noatime mount options
APFS is the latest file system of MacOS which support SSD Trim command. In the Niresh Hackintosh Disc, it doesn’t come with the drivers, which I cannot install MacOS on my SSD. Therefore, I need to make conversion after installation. Luckily, the installation is very simple.
1. Boot into recovery mode
2. Unmount the Disk
3. Edit => Convert to APFS
In unix file system, it has a function named atime, which will log the time for every file access. It is no big deal in Magnetic hard disk, however, it is a matter for SSD as it hugely increase the wearing of SSD. Furthermore, because it saves a write operation, the disk will also perform slightly faster, especially for compiling program
1. https://gist.github.com/dmitryd/16902ad3a5defd42d012
2. Reboot, check with “mount”
8. Homebrew, https://brew.sh/
/usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
There are some pitfall which I have encountered, the best recommendation is still strictly follow the tonymacx86 purchase list, and don’t even derivate a single model from it.
https://www.tonymacx86.com/buyersguide/building-a-customac-hackintosh-the-ultimate-buyers-guide/
The pitfall are as followed.
1. Sandy Bridge CPU E3 1275 iGPU is HD P3000 which has a different hardware device ID with a standard Sandy Bridge HD3000. Inject Intel and FakeIntelGPU may work, but fail due to point 2
2. Mix of Sandy Bridge CPU + Ivy Bridge Mainboard will cause issue. Apple treats mainboard as the platform, which you need to match up with CPU and iGPU by configuration SMIBIOS. I cannot get the iGPU working and need to use a GT1030 card
3. MacOS is not happy with nVidia Maxwell and Pascal GPU out of the box, that’s the 9xx and 10xx family. They cannot run on Mojave OR Catalina right now. For High Sierra, nVidia has provide official Drivers named Nvidia Web Driver, You need to pick the right version against your current Mac Version, 10.13.0 has different driver from 10.13.6.
4. Picking a Kelper Nvidia GPU is a MUST for Mojave or Catalina. Comments from forum suggest RX570. I am wondering if a RX460 from China, which is the salvage of Crypto Mining Machine is a good deal
4. You MUST go to Recovery Mode and UNMOUNT the system volume to convert the primary partition to APFS
5. Don’t need to install the NullCPUManagement.kext. The AppleIntelCPUPowerManagement.kext should be fine and working with the Clover C-State parameters
sudo xcode-select --install /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" brew install git [email protected] nvm wireguard-tools nvm use 14 brew tap hashicorp/tap brew install hashicorp/tap/terraform curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target / brew install --cask intel-power-gadget clover-configurator brew install --cask iterm2 cheatsheet intel-haxm brew install --cask maczip foxitreader brew install --cask google-chrome firefox xx brew install --cask microsoft-office brew install --cask sublime-merge sublime-text brew install --cask visual-studio-code intellij-idea-ce pycharm-ce dbeaver-community brew install --cask wireguard-tools qbittorrent vlc brew install --cask whatsapp telegram microsoft-teams brew install --cask spotify https://officecdn.microsoft.com/pr/C1297A47-86C4-4C1F-97FA-950631F94777/MacAutoupdate/Microsoft_Office_16.29.19090802_Installer.pkg
WebDAV Server on Apache
MS Office has native support of WebDAV, you can quickly setup a WebDAV server in Apache for testing, instead of spinning up the fully functioning SharePoint Server.
Here is the quick settings for setting up a Apache WebDAV server.
a2enmod dav
a2enmod dav_fs
And then add a new site in /etc/apache2/sites-available/ as followed.
<VirtualHost *:80>
ServerName webdav.jimmysyss.com
ServerAdmin webmaster@localhost
ServerAlias webdav.jimmysyss.com
DocumentRoot /var/www/webdav
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
<Directory /var/www/webdav/>
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
allow from all
</Directory>
Alias /svn /var/www/webdav/svn
<Location /svn>
DAV On
</Location>
</VirtualHost>
# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
Meltdown and Spectre affects you?
These few vulnerabilities claims to be the most widely spread potential security issue in the last few years. M$ and Linux has provided corresponding patch in fixing it. However, the fix is not free, it usually counts for ~10% of performance reduction, the effect may be magnified in IO intensive usage.
I found my machine compiling our source slower than before by slim margin (~30 sec difference) and try to dig out the reason of the slowness.
There are ways to stop the patch in either Linux and Windows.
Linux
http://wayoflinux.com/blog/meltdown-spectre-performance
Windows
https://www.grc.com/inspectre.htm
Honestly, I am not a terrorist nor government officers, given my notebook is sitting behind the company firewall, I am safe to reclaim my PC performance. You may check that out too, but do at your own risk.
Self Reflection on IT company structure
Interesting stories to share
https://dev.to/henrylim96/reverse-engineering-cathay-pacifics-seat-selection-page-43od
I am imagining how’s CX handle this incident internally and how to avoid. CX “supposes” to have good system and control, every thing should have check and balance. Who should be responsible for this?????
Imagining there are standard in-house software development structure, different teams would have claims as followed.
Business User: IT is shit, making rubbish, charge me so much (transfer pricing). Fire them all!!! (Yes, they did, I think they deserve)
Business Analyst: I have already documented the user requirement and expectation, modifying the ticket class is not a valid use case, it should be security team responsibility, definitely not my fault.
Security Team: My responsibility is using the million dollars app scanner, network scanner, IDS (Intrusion detection system) and XYZXYZ (lots of buzz words) to do regular checking, I just know scanning, but nothing about business.
Dev Team: Such validation is not written on the specification, it makes no sense for me to implement it.
Micro-service Dev Team: This logic suppose to be validated by XXX Team, it is not my responsibility to re-validate and I am NOT TOLD TO DO SO.
Architect: (Playing fingers) It is business use case, not on my dish.
QA: BA, pls confirm(The requirement). DB Team, pls confirm. Dev Team, pls confirm. I don’t know who should I ask to confirm. I am just a test plan executor. I can be BA if I know the business well, I could be a programmer if I can code test case. This incident is definitely not my issue.
DB Team: I only deal with DB Structure and constraint.
Support / Customer Service: The phones are all ringing, the customer has fxxked us so hard. Dev Team, pls advice. BA, pls advice. DB Team, pls advice. Architect Team, pls advice.
Internal Audit Team: I am just a Business Man, knowing how to present and tender external party for auditing. I don’t really know how the system works, how could I audit to this level?
The management may claim everyone is responsible, but eventually it means no one is responsible.
It is ironic that simple script kiddie technique can break several million dollars project, and destroy the brand. I don’t think this is the only bug on the system or any other multi billions dollars organization, from banks, to hospitals, to varies online providers.
Disclaimer: Any similarity is mere coincidence
Build my Fusion Drive with LVM-Cache
LVM Cache is a interesting feature that I saw some web review on the web. It can speed up traditional mechanical disk with a cache partition on SSD. Essentially the concept is the same as Windows Readyboost or Fusion Drive, which the caching is controlled by firmware.
Resize the SSD
e2fsck /dev/sda1 resize2fs /dev/sda1 100000M
Use GParted to adjust the partition size
Mark Data(sdb1), Cache(sda2) and Meta(sda3) as LVM PV
sudo pvcreate /dev/sdb1 sudo pvcreate /dev/sda2 sudo pvcreate /dev/sda3
Create Volume Group with the PVs
# Must spare some space sudo vgcreate VG /dev/sdb1 /dev/sda2 /dev/sda3 sudo lvcreate -l 95%FREE -n data VG /dev/sdb1 sudo lvcreate -l 95%FREE -n cache VG /dev/sda2 sudo lvcreate -l 95%FREE -n meta VG /dev/sda3
Create Cache Pool and config cache mode as Writeback (improve read / write performance)
sudo lvconvert --type cache-pool --poolmetadata VG/meta VG/cache sudo lvconvert --type cache --cachepool VG/cache --cachemode writeback VG/data
In case you are unlucky that u encounter the cache corruption. You need to execute the following commands to rebuild the cache
vgchange -a y VG lvchange -a y VG/data lvconvert --repair VG/data
Reference:
http://man7.org/linux/man-pages/man7/lvmcache.7.html
Nginx per user directory
It is common for hosting company to share the same host and create per user directory, so that every user can browse with the following url.
http://localhost/~jimmy/index.html
It can be achieved easily by nginx configuration.
sudo vi /etc/nginx/sites-available/default
Add the following code under “server” section
location ~ ^/~(.+?)(/.*)?$ {
alias /home/$1/www$2;
autoindex on;
}
Add the user to www-data group
sudo usermod -aG www-data $USER
Change the www directory under user home to mod 755, so that others can access the folder with execute right
chown 755 -R ~/www/
Some notes
sshpass -p ‘*******’ rsync -avzh -e ‘ssh -p 40022’ XXXXFILEXXXX pi@XXXXX:Downloads/
# Search for my current IP
dig +short myip.opendns.com @resolver1.opendns.com
We can use openssl command to verify the connection.
openssl s_client -connect 75.124.180.124:11405 -cert cont-public.cert -key cont.key
In order to create a java keystore, we have to create a P12 keystore first and then use keytool to import as Java Keystore. The commands are as followed.
openssl pkcs12 -export -in cont-public.cert -inkey cont.key -out cont20161209.p12 -name initiator
keytool -importkeystore -destkeystore initiator.jks -srckeystore cont20161209.p12 -srcstoretype PKCS12 -alias initiator
Finally, we “Trust” the public certificates
keytool -import -trustcacerts -file ullink.cert -alias ullink -keystore initiator.jks
And we can verify with the following command
keytool -list -v -keystore initiator.jks
RDBMS vs NoSQL vs NewSQL
SQL and traditional RDBMS is inevitably a key surviving skill for every programmer. SQL is good given that it is more or less an universal standard in database, or when we want to interact with any database. RDBMS is good because they provide ACID guarantee for programmer, which drastic simplify programmer life especially in web environment.
However, RDBMS suffers from scalability and concurrency problem when it comes to web scale. The common 1 master + N slaves or data sharing technique only postpone the problems by several times. It also posts a few limitations like Read-Write ratio and the partition key has to be carefully selected, which means the designers have to aware of the limitation.
Some people start moving on to NoSQL, whether it is NO SQL or NOT ONLY SQL is debatable. However, from an engineering point of view, NoSQL is a solution to a specific problem but not a silver bullet.
In general, NoSQL can be further divided into the following categories.
– Graph Database – Neo4j
– Document Base Database – MongoDB
– Key Value Database – Redis / Memcache
– Column Oriented Database – Cassandra
– Time Series Database (Extension) – Riak DB / OpenTSDB
For further details on NoSQL database, tap this link https://www.couchbase.com/pricing.
Each of them are solving a particular business model or use cases. For example, Graph DB are used to handle parties and relationships very efficiently. Document Base DB can handle hierarchy data better than RDBMS. We usually trade scalability for giving up Transaction capability.
The famous CAP theorem (Brewer’s theorem) describes the situation that Consistency, Availability and Partition Tolerance are mutually exclusive, we can only pick two out of three. Each NoSQL DB and RDBMS are following this rules with NO EXCEPTION.
SQL is still widely used as of today, since many software are not really web scale or the management doesn’t know or want to pay the cost for web scale. So, people are dreaming to have SQL & RDBMS capabilities while having the NoSQL scalability? It becomes the goal for NewSQL. Google (The God, again) has published a paper for the concept of Spanner, which is now in production in Google Cloud Platform.
https://research.google.com/archive/spanner.html
In short, it tries to detach the TX manager and the underlying Storage Manager, so that for each query or update, the TX Manager can acquire the relevant Storage managers. Since the Storage is handle locally, the storage itself is usually bigger in size (64MB) and can be distributed. It fits perfectly in AWS S3 or Google Cloud Storage. However, as it involves Network operations, the overall performance should be slower than a local DB with smaller dataset.
There are other local implementations, like VoltDB or CockroachDB.
SailsJS Hello World
Sails JS is a full MVC framework that build on Express and io.js. It looks easy to use and I have tried to incorporated different functionalities in it.
You may find my hello world in the following links
https://github.com/jimmysyss/sails-hw
I have included the following in the projects.
1. Passport.js
2. Swaggers.js
3. React + Webpack
4. Sequelize
I have also configured a few settings in the Sails JS Project.
1. CSRF
2. Winston